作者知乎账号:邪王真眼最强
Part1b站一个视频的爬取思路分析
网址:”
第一步,先对视频网页进行抓包,可以发现这两个请求是视频相关的。
接着我们可以用python将两个url都请求一遍,并且保存文件,都以mp4格式保存。
代码:
# 开发时间: 2023/5/24 0:11# 作 者:星辰之梦梦import requestsheaders = { "referer": "https://www.bilibili.com", "origin": "https://www.bilibili.com", "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36",}# 100028url1 = "https://upos-sz-mirrorcos.bilivideo.com/upgcxcode/73/12/836471273/836471273-1-100028.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1684865947&gen=playurlv2&os=cosbv&oi=0&trid=9df467665ce34bc8b1a9108af0a27cd1u&mid=647250039&platform=pc&upsig=0da697973b0a4359957bc8bfaf3648f1&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,mid,platform&bvc=vod&nettype=0&orderid=0,3&buvid=ADFF7A65-40F1-F25C-C91B-8FFE569D520E16369infoc&build=0&agrr=1&bw=126933&logo=80000000"# 30280url2 = "https://upos-sz-mirrorcos.bilivideo.com/upgcxcode/73/12/836471273/836471273_nb3-1-30280.m4s?e=ig8euxZM2rNcNbdlhoNvNC8BqJIzNbfqXBvEqxTEto8BTrNvN0GvT90W5JZMkX_YN0MvXg8gNEV4NC8xNEV4N03eN0B5tZlqNxTEto8BTrNvNeZVuJ10Kj_g2UB02J0mN0B5tZlqNCNEto8BTrNvNC7MTX502C8f2jmMQJ6mqF2fka1mqx6gqj0eN0B599M=&uipk=5&nbs=1&deadline=1684865947&gen=playurlv2&os=cosbv&oi=0&trid=9df467665ce34bc8b1a9108af0a27cd1u&mid=647250039&platform=pc&upsig=4419c16cfb65b59180d74edc64066a69&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,mid,platform&bvc=vod&nettype=0&orderid=0,3&buvid=ADFF7A65-40F1-F25C-C91B-8FFE569D520E16369infoc&build=0&agrr=1&bw=40149&logo=80000000"resp1 = requests.get(url1, headers=headers).contentresp2 = requests.get(url2, headers=headers).contentwith open("111.mp4", mode='wb') as file1: file1.write(resp1)with open("222.mp4", mode='wb') as file2: file2.write(resp2)
下载完成后,打开发现111.mp4文件中存储的是无音频的视频,而222.mp4文件中存储的是音频(无视频)。因此我们后面需要将视频文件和音频文件进行合并,会用到ffmpeg软件。
现在我们需要实现 请求 视频网页的地址(即视频号) 得到上述视频url 音频url。因此回到 视频网页,在elemens中用url1中的关键参数(1-100028.m4s)搜索。发现在script标签中,并且以js数据格式存放(如下图),接着打开网页源代码再次搜索,也能得到搜索结果。因此我们只需要请求 视频网页的地址(即视频号)并解析拿到script中的视频url和音频url。
代码:
import requestsimport reimport jsonfrom lxml import etreeimport osurl = "https://www.bilibili.com/video/BV16e4y1k7Rs/?spm_id_from=333.999.0.0&vd_source=d8494042caaa3e41d56c7e04cc1669dd"headers = { "referer": "https://www.bilibili.com", "origin": "https://www.bilibili.com", "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36",}# 第一步 请求 视频网页的地址,拿到网页数据resp_ = requests.get(url, headers=headers)resp = resp_.textresp_.close()tree = etree.HTML(resp)# 第二步 从网页数据中提取视频标题title = tree.xpath('//h1/text()')[0]# print(title)# /html/head/script[3]/text()# 第三步 从网页数据中提取视频url和音频urltry: tree1 = tree.xpath('/html/head/script[3]/text()')[0] tree1 = re.sub(r'window.__playinfo__=', '', tree1) # print(tree1) tree1 = json.loads(tree1)except: tree1 = tree.xpath('/html/head/script[4]/text()')[0] tree1 = re.sub(r'window.__playinfo__=', '', tree1) # print(tree1) tree1 = json.loads(tree1)video = tree1['data']['dash']['video'][0]video_url = video['backupUrl'][0]print(video_url)audio = tree1['data']['dash']['audio'][0]audio_url = audio['backupUrl'][0]print(audio_url)### 上述video_url 即视频url。audio_url 即音频url'''resp1 = requests.get(video_url, headers=headers).contentresp2 = requests.get(audio_url, headers=headers).contentwith open("111.mp4", mode='wb') as file1: file1.write(resp1)with open("222.mp4", mode='wb') as file2: file2.write(resp2)'''
到这里,我们已经实现从视频网页地址直接拿到视频文件和音频文件。但是他们是分开的。接着我们就继续讲解如何合并视频和音频。
Part2Fmpeg的安装及配置
FFmpeg是一套功能包括视频采集功能、视频格式转换、视频抓图、给视频加水印等的开源计算机程序。
官网下载:Download FFmpeg
以windows为例
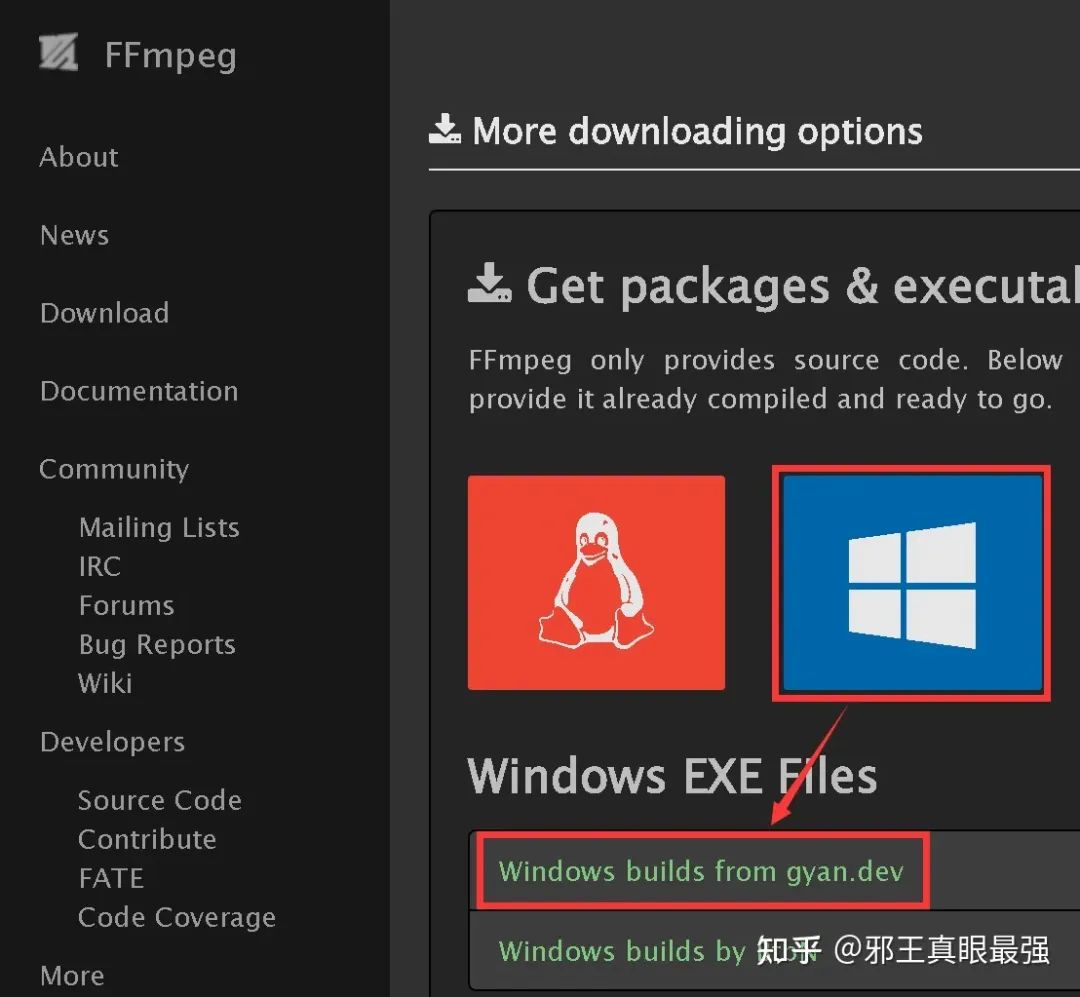
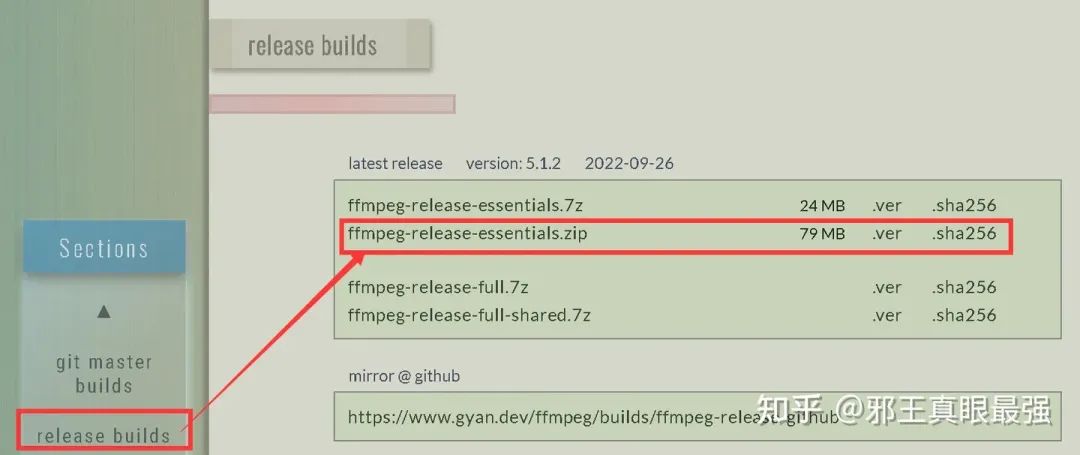
下载完成后解压文件。将bin文件夹的路径添加进环境变量
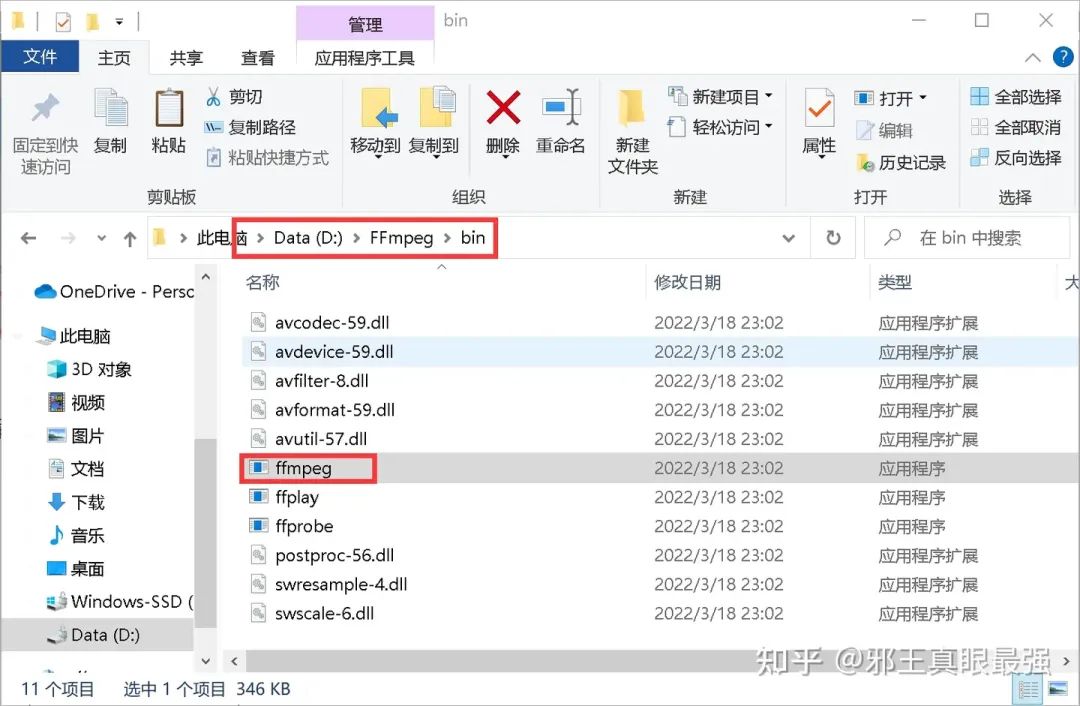
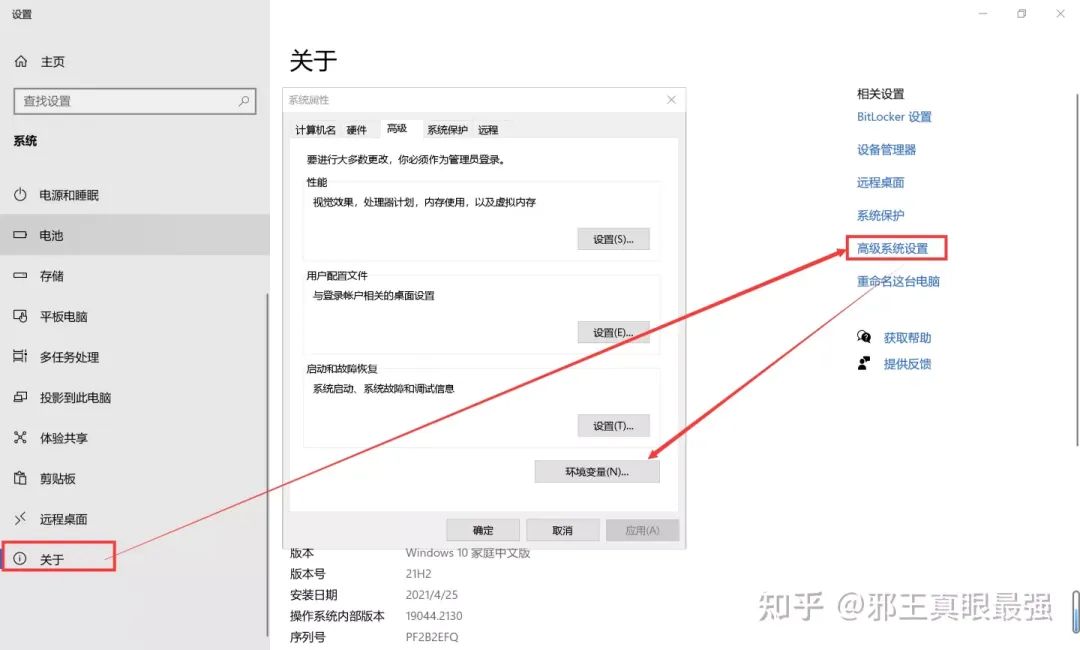
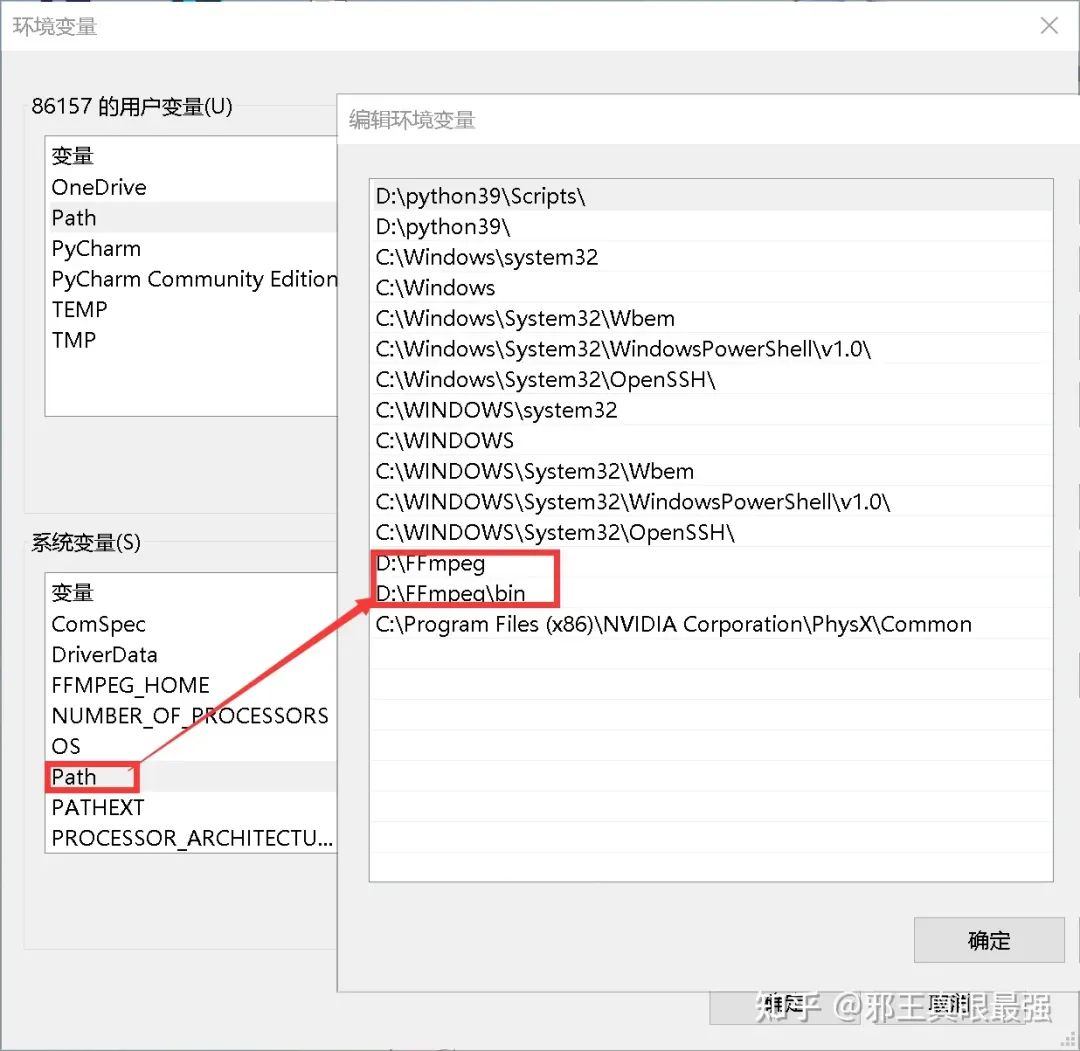
到这里,FFmpeg配置就完成了,接下来就是实现合并音频和视频了。
Part3合并音频和视频代码
# 省略以上代码# ①创建保存视频的文件夹e = "b站视频"if not os.path.exists(e): os.mkdir(e)# ②保存好视频和音频 注意变量title0为原音频和视频的标题。new_title为合并后的文件标题with open("b站视频/" + f"{title0}.mp4", mode='wb') as f: f.write(resp1)with open("b站视频/" + f"{title0}.acc", mode='wb') as x: x.write(resp2)# ③利用FFmpeg合并音频和视频文件,并且将原来的两个文件删除# 注意字符串中的格式。。' -i -i -acodec copy -vcodec copy 'com = f'D:/FFmpeg/bin/ffmpeg.exe -i "b站视频/{title0}.mp4" -i "b站视频/{title0}.acc" -acodec copy -vcodec copy "b站视频/{new_title}.mp4"'os.system(com)os.remove(f"b站视频/{title0}.mp4")os.remove(f"b站视频/{title0}.acc")
Part4爬取单个视频的代码
import requestsimport reimport jsonfrom lxml import etreeimport ose = "b站视频"if not os.path.exists(e): os.mkdir(e)while True: ''' 下载最高质量视频 ''' url = input("请输入url:") # url = "https://www.bilibili.com/video/BV17K411B7mC/" headers = { # 如果你有b站会员,添加cookie即可下载最高高画质视频 # "cookie": "", "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36", } resp_ = requests.get(url, headers=headers) resp = resp_.text resp_.close() tree = etree.HTML(resp) title = tree.xpath('//h1/text()')[0] # print(title) # /html/head/script[3]/text() try: tree1 = tree.xpath('/html/head/script[4]/text()')[0] tree1 = re.sub(r'window.__playinfo__=', '', tree1) tree1 = json.loads(tree1) except: # print("不是script[4]") tree1 = tree.xpath('/html/head/script[3]/text()')[0] tree1 = re.sub(r'window.__playinfo__=', '', tree1) tree1 = json.loads(tree1) video = tree1['data']['dash']['video'][0] video_url = video['backupUrl'][0] # print(video_url) audio = tree1['data']['dash']['audio'][0] audio_url = audio['backupUrl'][0] # print(audio_url) print("正在下载", title) headers521 = { "referer": url, "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36", } resp1_ = requests.get(video_url, headers=headers521) resp1 = resp1_.content resp2_ = requests.get(audio_url, headers=headers521) resp2 = resp2_.content resp1_.close() resp2_.close() new_title = re.sub(r'[\/:*?"|n]', '_', title) title0 = new_title + "0" with open("b站视频/" + f"{title0}.mp4", mode='wb') as f: f.write(resp1) with open("b站视频/" + f"{title0}.acc", mode='wb') as x: x.write(resp2) com = f'D:/FFmpeg/bin/ffmpeg.exe -i "b站视频/{title0}.mp4" -i "b站视频/{title0}.acc" -acodec copy -vcodec copy "b站视频/{new_title}.mp4"' os.system(com) os.remove(f"b站视频/{title0}.mp4") os.remove(f"b站视频/{title0}.acc") print("over!!!", new_title)
Part5爬用户的视频选集对应的所有视频
如图所示这种的类型视频:

思路:首先根据视频号,请求对应网址,把所有视频标题提取出来。再用线程池,下载每一集的视频。
import requestsimport refrom concurrent.futures import ThreadPoolExecutorimport osimport jsonfrom lxml import etree# from pprint import pprintdef get_titles(url): # 创建文件夹bilibili file = "b站视频" if not os.path.exists(file): os.mkdir(file) # 通过请求url_title解析拿到每一个分视频的标题 headers = { "referer": url, "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36", } url_title = "https://api.bilibili.com/x/player/pagelist?bvid=" + q + "&jsonp=jsonp" response = requests.get(url=url_title, headers=headers).json() # print(response) # titles保存所有标题 titles = [] ss = response['data'] for s in ss: title = str(s['page']) + "、" + s['part'] titles.append(title) return titlesdef download(url, title, cookie): headers = { "cookie": cookie, "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36", "Referer": "https://space.bilibili.com/647250039/video", } res = requests.get(url=url, headers=headers).text # print(res) page = etree.HTML(res) try: tree1 = page.xpath('/html/head/script[4]/text()')[0] tree1 = re.sub(r'window.__playinfo__=', '', tree1) tree1 = json.loads(tree1) except: # print("不是script[4]") tree1 = page.xpath('/html/head/script[3]/text()')[0] tree1 = re.sub(r'window.__playinfo__=', '', tree1) tree1 = json.loads(tree1) # pprint(tree1['data']['dash']['video']) id_list = for video in tree1['data']['dash']['video']] video_url = tree1['data']['dash']['video'][id_list.index(max(id_list))]['backupUrl'][0] id_list = for audio in tree1['data']['dash']['audio']] audio_url = tree1['data']['dash']['audio'][id_list.index(max(id_list))]['backupUrl'][0] # print(video_url) # print(audio_url) print("正在下载", title) headers521 = { "referer": url, "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36", } resp1_ = requests.get(video_url, headers=headers521) resp1 = resp1_.content resp2_ = requests.get(audio_url, headers=headers521) resp2 = resp2_.content resp1_.close() resp2_.close() new_title = re.sub(r'[\/:*?"|n]', '_', title) title0 = new_title + "0" with open("b站视频/" + f"{title0}.mp4", mode='wb') as f: f.write(resp1) with open("b站视频/" + f"{title0}.acc", mode='wb') as x: x.write(resp2) com = f'D:/FFmpeg/bin/ffmpeg.exe -i "b站视频/{title0}.mp4" -i "b站视频/{title0}.acc" -acodec copy -vcodec copy "b站视频/{new_title}.mp4"' os.system(com) os.remove(f"b站视频/{title0}.mp4") os.remove(f"b站视频/{title0}.acc") print("over!!!", new_title)if __name__ == '__main__': # 如果有b站会员,添加cookie也许可下载最高高画质视频 cookie = "" q = input("请输入一个含多个视频的视频号:") url = "https://www.bilibili.com/video/" + q + "?" titles = get_titles(url) print("拿到标题", titles) pool = ThreadPoolExecutor(10) for id__, title in enumerate(titles): url2 = url + "p" + str(id__+1) pool.submit(download, url2, title, cookie) pool.shutdown(wait=True)
限时特惠:本站每日持续更新海量各大内部网赚创业教程,会员可以下载全站资源点击查看详情
站长微信:11082411
